Werbung
Glauben Sie an die Idee, dass etwas, das einmal im Internet veröffentlicht wurde, für immer veröffentlicht wird? Nun, heute werden wir diesen Mythos zerstreuen.
Die Wahrheit ist, dass es in vielen Fällen durchaus möglich ist, Informationen aus dem Internet zu löschen. Sicher, es gibt eine Aufzeichnung von Webseiten, die gelöscht wurden, wenn Sie die durchsuchen Wayback-Maschine, Recht? Ja, absolut. Auf der Wayback-Maschine gibt es Aufzeichnungen über Webseiten, die viele Jahre zurückliegen - Seiten, die Sie bei einer Google-Suche nicht finden, weil die Webseite nicht mehr vorhanden ist. Jemand hat es gelöscht oder die Website wurde geschlossen.
Daran führt kein Weg vorbei, oder? Informationen werden für immer in den Stein des Internets eingraviert sein, dort für Generationen zu sehen? Nun, nicht genau.
Die Wahrheit ist, dass es zwar schwierig oder unmöglich sein kann, wichtige Nachrichten zu löschen, die sich wie ein Virus von einer Nachrichtenwebsite oder einem Blog zu einem anderen verbreitet haben. Es ist eigentlich ganz einfach, eine Webseite oder mehrere Webseiten vollständig aus allen Existenzdatensätzen zu entfernen - um diese Seite sowohl für Suchmaschinen als auch für Suchmaschinen zu entfernen das
Wayback-Maschine Mit der neuen Wayback-Maschine können Sie in der Internetzeit visuell zurückreisenEs scheint, dass die Websitebesitzer seit dem Start der Wayback-Maschine im Jahr 2001 beschlossen haben, das Alexa-basierte Back-End wegzuwerfen und es mit ihrem eigenen Open-Source-Code neu zu gestalten. Nach Durchführung von Tests mit dem ... Weiterlesen . Es gibt natürlich einen Haken, aber dazu kommen wir.3 Möglichkeiten, Blogseiten aus dem Netz zu entfernen
Die erste Methode wird von den meisten Website-Eigentümern verwendet, da sie es nicht besser wissen - einfach Webseiten löschen. Dies kann passieren, weil Sie festgestellt haben, dass Ihre Website doppelte Inhalte enthält, oder weil Sie eine Seite haben, die nicht in den Suchergebnissen angezeigt werden soll.
Löschen Sie einfach die Seite
Das Problem beim vollständigen Löschen von Seiten von Ihrer Website besteht darin, dass Sie die Seite bereits auf der Website eingerichtet haben Im Internet gibt es wahrscheinlich Links von Ihrer eigenen Website sowie externe Links von anderen Websites zu dieser bestimmten Website Seite. Wenn Sie es löschen, erkennt Google Ihre Seite sofort als fehlende Seite.
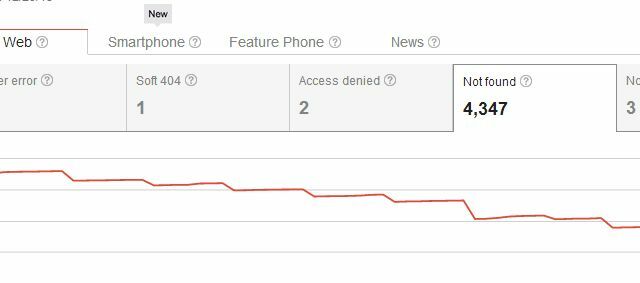
Beim Löschen Ihrer Seite haben Sie also nicht nur ein Problem mit Crawling-Fehlern "Nicht gefunden" für sich selbst erstellt, sondern auch ein Problem für alle Benutzer, die jemals auf die Seite verlinkt haben. Normalerweise sehen Benutzer, die über einen dieser externen Links auf Ihre Website gelangen, Ihre 404-Seite, bei der es sich nicht um eine handelt Hauptproblem, wenn Sie den benutzerdefinierten 404-Code von Google verwenden, um Nutzern hilfreiche Vorschläge zu machen, oder Alternativen. Aber Sie würden denken, es könnte elegantere Möglichkeiten geben, Seiten aus Suchergebnissen zu löschen, ohne alle diese 404 für vorhandene eingehende Links zu starten, oder?
Nun, das gibt es.
Entfernen Sie eine Seite aus den Google-Suchergebnissen
Zunächst sollten Sie verstehen, dass die Webseite, die Sie aus den Google-Suchergebnissen entfernen möchten, keine Seite Ihrer eigenen Website ist. Dann haben Sie kein Glück, es sei denn, es gibt rechtliche Gründe oder die Website hat Ihre persönlichen Daten ohne Ihre Daten online gestellt Genehmigung. Wenn dies der Fall ist, verwenden Sie Google Fehlerbehebung beim Entfernen um eine Anfrage zu senden, die Seite aus den Suchergebnissen zu entfernen. Wenn Sie einen gültigen Fall haben, kann es sein, dass Sie Erfolg haben, wenn Sie die Seite entfernen - natürlich haben Sie nur noch größeren Erfolg Kontaktaufnahme mit dem Eigentümer der Website So entfernen Sie falsche persönliche Informationen im InternetDer Online-Datenschutz ist nicht mehr garantiert. Erfahren Sie, wie Sie eine Website melden und persönliche Informationen aus dem Internet entfernen. Weiterlesen wie ich bereits 2009 beschrieben habe.
Wenn sich die Seite, die Sie aus den Suchergebnissen entfernen möchten, auf Ihrer eigenen Website befindet, haben Sie Glück. Alles was Sie tun müssen, ist eine zu erstellen robots.txt Stellen Sie sicher, dass Sie entweder die bestimmte Seite, die Sie nicht in den Suchergebnissen haben möchten, oder das gesamte Verzeichnis mit den Inhalten, die Sie nicht indizieren möchten, nicht zugelassen haben. So sieht das Blockieren einer einzelnen Seite aus.
User-Agent: * Nicht zulassen: /my-deleted-article-that-i-want-removed.html
Sie können Bots daran hindern, ganze Verzeichnisse Ihrer Site wie folgt zu crawlen.
User-Agent: * Nicht zulassen: / content-about-personal-stuff /
Google hat eine ausgezeichnete Support-Seite Dies kann Ihnen beim Erstellen einer robots.txt-Datei helfen, wenn Sie noch nie zuvor eine erstellt haben. Dies funktioniert sehr gut, wie ich kürzlich in einem Artikel über erklärt habe Strukturierung von Syndication-Deals So verhandeln Sie über Syndication-Angebote und schützen Ihre SuchrankingsSyndizieren ist heutzutage der letzte Schrei. Aber plötzlich könnten Sie feststellen, dass der Syndizierungspartner in den Suchergebnissen für eine Geschichte, die Sie ursprünglich geschrieben haben, höher aufgeführt ist als Sie! Schützen Sie Ihre Suchrankings. Weiterlesen damit sie Sie nicht verletzen (indem Sie die Syndizierungspartner bitten, die Indizierung ihrer Seiten, auf denen Sie syndiziert sind, nicht zuzulassen). Sobald mein eigener Syndication-Partner dem zugestimmt hatte, verschwanden die Seiten, auf denen Inhalte aus meinem Blog dupliziert wurden, vollständig aus den Suchlisten.

Nur die Hauptwebsite belegt den dritten Platz für die Seite, auf der unser Titel aufgeführt ist, aber mein Blog ist jetzt sowohl an der ersten als auch an der zweiten Stelle aufgeführt. Etwas, das fast unmöglich gewesen wäre, wenn eine Website mit höherer Autorität die duplizierte Seite indexiert hätte.
Was viele Menschen nicht merken, ist, dass dies auch mit dem Internetarchiv (der Wayback-Maschine) möglich ist. Hier sind die Zeilen, die Sie zu Ihrer robots.txt-Datei hinzufügen müssen, damit dies geschieht.
Benutzeragent: ia_archiver. Nicht zulassen: / sample-category /
In diesem Beispiel fordere ich das Internetarchiv auf, alle Elemente im Unterverzeichnis "Beispielkategorie" auf meiner Website von der Wayback-Maschine zu entfernen. Das Internetarchiv erklärt dies auf der Hilfeseite zum Ausschluss. Hier erklären sie auch, dass „das Internetarchiv nicht daran interessiert ist, Zugang zu Websites oder anderen Internetdokumenten zu bieten, deren Autoren ihre Materialien nicht in der Sammlung haben möchten.“
Dies widerspricht der weit verbreiteten Überzeugung, dass alles, was ins Internet gestellt wird, für alle Ewigkeit in das Archiv aufgenommen wird. Nein - Webmaster, denen der Inhalt gehört, können den Inhalt mithilfe des robots.txt-Ansatzes gezielt aus dem Archiv entfernen lassen.
Entfernen Sie eine einzelne Seite mit Meta-Tags
Wenn Sie nur einige einzelne Seiten haben, die Sie aus den Google-Suchergebnissen entfernen möchten, müssen Sie den robots.txt-Ansatz nicht verwenden Sie können den einzelnen Seiten einfach das richtige Meta-Tag „Roboter“ hinzufügen und die Roboter anweisen, keine Links zu indizieren oder zu folgen Seite.
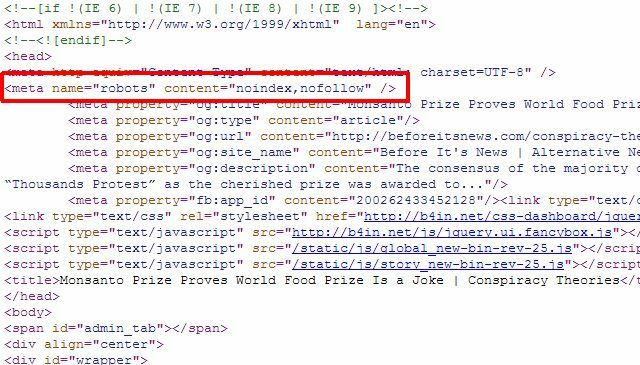
Sie können das obige Meta "Roboter" verwenden, um zu verhindern, dass Roboter die Seite indizieren, oder Sie können dem Google-Roboter dies ausdrücklich mitteilen Nicht zu indizieren, damit die Seite nur aus den Google-Suchergebnissen entfernt wird und andere Suchroboter weiterhin auf die Seite zugreifen können Inhalt.
Es liegt ganz bei Ihnen, wie Sie verwalten möchten, was Roboter mit der Seite tun und ob die Seite aufgelistet wird oder nicht. Für nur einige einzelne Seiten ist dies möglicherweise der bessere Ansatz. Verwenden Sie die robots.txt-Methode, um ein gesamtes Inhaltsverzeichnis zu entfernen.
Die Idee, Inhalte zu „entfernen“
Diese Art stellt den ganzen Begriff des „Löschens von Inhalten aus dem Internet“ auf den Kopf. Technisch gesehen, wenn Sie alle Ihre eigenen Links zu einer Seite auf Ihrer Website entfernen und diese aus der Google-Suche und der entfernen Internet-Archiv Mit der robots.txt-Technik wird die Seite in jeder Hinsicht aus dem Internet „gelöscht“. Das Coole ist jedoch, dass Links zu dieser Seite weiterhin funktionieren und Sie keine 404-Fehler für diese Besucher auslösen.
Dies ist ein „sanfterer“ Ansatz zum Entfernen von Inhalten aus dem Internet, ohne die vorhandene Linkpopularität Ihrer Website im gesamten Internet vollständig zu beeinträchtigen. Letztendlich liegt es an Ihnen, wie Sie verwalten, welche Inhalte von Suchmaschinen und dem Internetarchiv gesammelt werden, aber immer Denken Sie daran, dass trotz der Aussagen der Leute über die Lebensdauer von Dingen, die online veröffentlicht werden, alles in Ihrem Bereich liegt Steuerung.
Ryan hat einen BSc-Abschluss in Elektrotechnik. Er hat 13 Jahre in der Automatisierungstechnik, 5 Jahre in der IT gearbeitet und ist jetzt Apps Engineer. Als ehemaliger Managing Editor von MakeUseOf sprach er auf nationalen Konferenzen zur Datenvisualisierung und wurde im nationalen Fernsehen und Radio vorgestellt.


