Werbung
Wenn du eine Website betreiben 10 Möglichkeiten, eine kleine und einfache Website ohne Overkill zu erstellenWordPress kann ein Overkill sein. Wie diese anderen hervorragenden Dienste beweisen, ist WordPress nicht das A und O bei der Erstellung von Websites. Wenn Sie einfachere Lösungen wünschen, können Sie aus einer Vielzahl auswählen. Weiterlesen Sie haben wahrscheinlich von einer robots.txt-Datei (oder dem "Robots-Ausschlussstandard") gehört. Unabhängig davon, ob Sie dies getan haben oder nicht, ist es an der Zeit, sich darüber zu informieren, da diese einfache Textdatei ein wichtiger Bestandteil Ihrer Website ist. Es mag unbedeutend erscheinen, aber Sie werden überrascht sein, wie wichtig es ist.
Schauen wir uns an, was eine robots.txt-Datei ist, was sie tut und wie Sie sie richtig für Ihre Site einrichten.
Was ist eine robots.txt-Datei?
Um zu verstehen, wie eine robots.txt-Datei funktioniert, müssen Sie wissen ein bisschen über Suchmaschinen Wie funktionieren Suchmaschinen?Für viele Menschen ist Google das Internet. Es ist wohl die wichtigste Erfindung seit dem Internet selbst. Und obwohl sich Suchmaschinen seitdem stark verändert haben, sind die zugrunde liegenden Prinzipien immer noch dieselben. Weiterlesen . Die Kurzversion ist, dass sie "Crawler" senden, also Programme, die das Internet nach Informationen durchsuchen. Sie speichern dann einige dieser Informationen, damit sie später darauf zugreifen können.
Diese Crawler, auch als "Bots" oder "Spider" bekannt, finden Seiten von Milliarden von Websites. Suchmaschinen geben ihnen Anweisungen, wohin sie gehen sollen, aber einzelne Websites können auch mit den Bots kommunizieren und ihnen mitteilen, welche Seiten sie betrachten sollen.
Meistens machen sie tatsächlich das Gegenteil und sagen ihnen, welche Seiten sie haben sollte nicht schau dir an. Dinge wie Verwaltungsseiten, Backend-Portale, Kategorie- und Tag-Seiten und andere Dinge, die Websitebesitzer nicht in Suchmaschinen anzeigen möchten. Diese Seiten sind für Benutzer weiterhin sichtbar und für jeden zugänglich, der über eine Berechtigung verfügt (häufig für alle).
Indem Sie diesen Spinnen sagen, dass sie einige Seiten nicht indizieren sollen, tut die robots.txt-Datei allen einen Gefallen. Wenn Sie in einer Suchmaschine nach „MakeUseOf“ gesucht haben, möchten Sie, dass unsere Verwaltungsseiten in den Rankings ganz oben stehen? Nein, das würde niemandem nützen. Deshalb weisen wir Suchmaschinen an, sie nicht anzuzeigen. Es kann auch verwendet werden, um zu verhindern, dass Suchmaschinen Seiten auschecken, die ihnen möglicherweise nicht dabei helfen, Ihre Website in Suchergebnissen zu klassifizieren.
Kurz gesagt, robots.txt teilt Webcrawlern mit, was zu tun ist.
Können Crawler robots.txt ignorieren?
Ignorieren Crawler jemals robots.txt-Dateien? Ja. In der Tat viele Crawler machen ignoriere es. Im Allgemeinen stammen diese Crawler jedoch nicht von seriösen Suchmaschinen. Sie stammen von Spammern, E-Mail-Erntemaschinen und andere Arten von automatisierten Bots Erstellen eines einfachen Webcrawlers zum Abrufen von Informationen von einer WebsiteWollten Sie schon immer Informationen von einer Website erfassen? Hier erfahren Sie, wie Sie einen Crawler schreiben, um auf einer Website zu navigieren und das zu extrahieren, was Sie benötigen. Weiterlesen das durchstreift das Internet. Es ist wichtig, dies zu berücksichtigen - Die Verwendung des Roboterausschlussstandards, um Bots anzuweisen, sich fernzuhalten, ist keine wirksame Sicherheitsmaßnahme. In der Tat könnten einige Bots Anfang Mit den Seiten sagst du ihnen, sie sollen nicht gehen.
Suchmaschinen tun jedoch, was Ihre robots.txt-Datei sagt, solange sie korrekt formatiert ist.
So schreiben Sie eine robots.txt-Datei
Es gibt einige verschiedene Teile, die in eine Roboterausschluss-Standarddatei aufgenommen werden. Ich werde sie hier einzeln aufschlüsseln.
User Agent-Erklärung
Bevor Sie einem Bot mitteilen, welche Seiten er nicht anzeigen soll, müssen Sie angeben, mit welchem Bot Sie sprechen. Meistens verwenden Sie eine einfache Deklaration, die "alle Bots" bedeutet. Das sieht so aus:
User-Agent: *Das Sternchen steht für "alle Bots". Sie können jedoch Seiten für bestimmte Bots angeben. Dazu müssen Sie den Namen des Bots kennen, für den Sie Richtlinien festlegen. Das könnte so aussehen:
User-Agent: Googlebot. [Liste der Seiten, die nicht gecrawlt werden sollen] Benutzeragent: Googlebot-Image / 1.0. [Liste der Seiten, die nicht gecrawlt werden sollen] Benutzeragent: Bingbot. [Liste der Seiten, die nicht gecrawlt werden sollen]Und so weiter. Wenn Sie einen Bot entdecken, der Ihre Website überhaupt nicht crawlen soll, können Sie dies ebenfalls angeben.
Informationen zu den Namen der Benutzeragenten finden Sie unter useragentstring.com [Nicht mehr verfügbar].
Seiten nicht zulassen
Dies ist der Hauptteil Ihrer Roboterausschlussdatei. Mit einer einfachen Erklärung weisen Sie einen Bot oder eine Gruppe von Bots an, bestimmte Seiten nicht zu crawlen. Die Syntax ist einfach. So können Sie den Zugriff auf alle Elemente im Verzeichnis "admin" Ihrer Website nicht zulassen:
Nicht zulassen: / admin /Diese Zeile würde verhindern, dass Bots Ihre Site.com/admin, Ihre Site.com/admin/login, Ihre Site.com/admin/files/secret.html und alles andere, was unter das Administratorverzeichnis fällt, crawlen.
Um eine einzelne Seite nicht zuzulassen, geben Sie sie einfach in der Zeile "Nicht zulassen" an:
Nicht zulassen: /public/exception.htmlJetzt wird die Seite "Ausnahme" nicht gezeichnet, aber alles andere im Ordner "public" wird gezeichnet.
Um mehrere Verzeichnisse oder Seiten einzuschließen, listen Sie sie einfach in den folgenden Zeilen auf:
Nicht zulassen: / privat / Nicht zulassen: / admin / Nicht zulassen: / cgi-bin / Nicht zulassen: / temp /Diese vier Zeilen gelten für den Benutzeragenten, den Sie oben im Abschnitt angegeben haben.
Wenn Sie verhindern möchten, dass Bots eine Seite Ihrer Website anzeigen, verwenden Sie Folgendes:
Nicht zulassen: /Festlegen unterschiedlicher Standards für Bots
Wie wir oben gesehen haben, können Sie bestimmte Seiten für verschiedene Bots angeben. Wenn Sie die beiden vorherigen Elemente kombinieren, sieht das folgendermaßen aus:
User-Agent: Googlebot. Nicht zulassen: / admin / Nicht zulassen: / private / User-Agent: bingbot. Nicht zulassen: / admin / Nicht zulassen: / privat / Nicht zulassen: / secret /Die Bereiche "Admin" und "Privat" sind in Google und Bing nicht sichtbar, aber Google sieht das "geheime" Verzeichnis, während Bing dies nicht tut.
Sie können allgemeine Regeln für alle Bots mithilfe des Asterisk-Benutzeragenten festlegen und Bots dann auch in den folgenden Abschnitten spezifische Anweisungen geben.
Alles zusammenfügen
Mit dem obigen Wissen können Sie eine vollständige robots.txt-Datei schreiben. Starten Sie einfach Ihren bevorzugten Texteditor (wir sind es Fans von Sublime 11 Erhabene Texttipps für Produktivität und einen schnelleren WorkflowSublime Text ist ein vielseitiger Texteditor und ein Goldstandard für viele Programmierer. Unsere Tipps konzentrieren sich auf effizientes Codieren, aber allgemeine Benutzer werden die Tastaturkürzel zu schätzen wissen. Weiterlesen hier) und lassen Sie Bots wissen, dass sie in bestimmten Teilen Ihrer Website nicht willkommen sind.
Wenn Sie ein Beispiel für eine robots.txt-Datei sehen möchten, gehen Sie einfach zu einer beliebigen Site und fügen Sie am Ende "/robots.txt" hinzu. Hier ist ein Teil der robots.txt-Datei von Giant Bicycles:
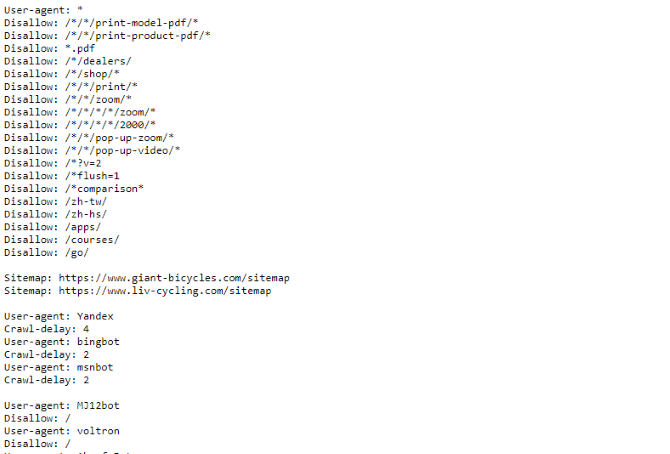
Wie Sie sehen, gibt es einige Seiten, die nicht in Suchmaschinen angezeigt werden sollen. Sie enthalten auch einige Dinge, über die wir noch nicht gesprochen haben. Schauen wir uns an, was Sie sonst noch in Ihrer Roboterausschlussdatei tun können.
Suchen Ihrer Sitemap
Wenn Ihre robots.txt-Datei den Bots sagt, wo nicht zu gehen, dein Sitemap macht das Gegenteil So erstellen Sie eine XML-Sitemap in 4 einfachen SchrittenEs gibt zwei Arten von Sitemaps: HTML-Seiten oder XML-Dateien. Eine HTML-Sitemap ist eine einzelne Seite, die Besuchern alle Seiten einer Website anzeigt und normalerweise Links zu diesen ... Weiterlesen und hilft ihnen zu finden, wonach sie suchen. Und während Suchmaschinen wahrscheinlich bereits wissen, wo sich Ihre Sitemap befindet, schadet es nicht, sie erneut zu informieren.
Die Deklaration für einen Sitemap-Speicherort ist einfach:
Sitemap: [URL der Sitemap]Das ist es.
In unserer eigenen robots.txt-Datei sieht es so aus:
Sitemap: //www.makeuseof.com/sitemap_index.xmlDas ist alles dazu.
Festlegen einer Crawling-Verzögerung
Die Crawl-Delay-Direktive teilt bestimmten Suchmaschinen mit, wie oft sie eine Seite auf Ihrer Website indizieren können. Es wird in Sekunden gemessen, obwohl einige Suchmaschinen es etwas anders interpretieren. Einige sehen eine Crawling-Verzögerung von 5 als Hinweis darauf, dass sie nach jedem Crawl fünf Sekunden warten müssen, um den nächsten zu starten. Andere interpretieren es als Anweisung, nur alle fünf Sekunden eine Seite zu crawlen.
Warum sollten Sie einem Crawler sagen, dass er nicht so viel wie möglich crawlen soll? Zu Bandbreite erhalten 4 Möglichkeiten, wie Windows 10 Ihre Internetbandbreite verschwendetVerschwendet Windows 10 Ihre Internetbandbreite? Hier erfahren Sie, wie Sie überprüfen und was Sie tun können, um dies zu stoppen. Weiterlesen . Wenn Ihr Server Probleme hat, mit dem Datenverkehr Schritt zu halten, möchten Sie möglicherweise eine Crawling-Verzögerung einleiten. Im Allgemeinen müssen sich die meisten Menschen darüber keine Sorgen machen. Große Websites mit hohem Datenaufkommen möchten jedoch möglicherweise ein wenig experimentieren.
So stellen Sie eine Durchforstungsverzögerung von acht Sekunden ein:
Kriechverzögerung: 8Das ist es. Nicht alle Suchmaschinen halten sich an Ihre Richtlinie. Aber es tut nicht weh zu fragen. Wie beim Nichtzulassen von Seiten können Sie für bestimmte Suchmaschinen unterschiedliche Crawling-Verzögerungen festlegen.
Hochladen Ihrer robots.txt-Datei
Sobald Sie alle Anweisungen in Ihrer Datei eingerichtet haben, können Sie sie auf Ihre Site hochladen. Stellen Sie sicher, dass es sich um eine Nur-Text-Datei mit dem Namen robots.txt handelt. Laden Sie es dann auf Ihre Website hoch, damit Sie es auf Ihrer Website.com/robots.txt finden.
Wenn Sie eine verwenden Content-Management-System 10 beliebtesten Online-Content-Management-SystemeDie Zeiten von handcodierten HTML-Seiten und dem Beherrschen von CSS sind lange vorbei. Installieren Sie ein Content Management System (CMS) und innerhalb weniger Minuten können Sie eine Website für die Welt freigeben. Weiterlesen Wie bei WordPress gibt es wahrscheinlich einen bestimmten Weg, den Sie dazu benötigen. Da es in jedem Content-Management-System unterschiedlich ist, müssen Sie die Dokumentation für Ihr System konsultieren.
Einige Systeme verfügen möglicherweise auch über Online-Schnittstellen zum Hochladen Ihrer Datei. Kopieren Sie dazu einfach die Datei, die Sie in den vorherigen Schritten erstellt haben, und fügen Sie sie ein.
Denken Sie daran, Ihre Datei zu aktualisieren
Der letzte Ratschlag, den ich geben werde, ist, gelegentlich Ihre Roboterausschlussdatei zu überprüfen. Ihre Site ändert sich und Sie müssen möglicherweise einige Anpassungen vornehmen. Wenn Sie eine merkwürdige Änderung im Suchmaschinenverkehr bemerken, sollten Sie auch die Datei überprüfen. Es ist auch möglich, dass sich die Standardnotation in Zukunft ändert. Wie alles andere auf Ihrer Website lohnt es sich, dies von Zeit zu Zeit zu überprüfen.
Von welchen Seiten schließen Sie Crawler auf Ihrer Website aus? Haben Sie einen Unterschied im Suchmaschinenverkehr bemerkt? Teilen Sie Ihre Ratschläge und Kommentare unten!
Dann ist ein Content-Strategie- und Marketingberater, der Unternehmen dabei hilft, Nachfrage und Leads zu generieren. Er bloggt auch über Strategie- und Content-Marketing auf dannalbright.com.


