Werbung
Code 42, das Unternehmen hinter CrashPlan hat sich dazu entschlossen Heimanwender vollständig aufgeben CrashPlan Shutters Cloud Backup für PrivatanwenderCode42, das Unternehmen hinter CrashPlan, hat angekündigt, dass es Heimanwender fallen lässt. CrashPlan for Home wird abgeschafft, und Code42 konzentriert sich stattdessen ausschließlich auf Unternehmens- und Geschäftskunden. Weiterlesen . Ihre äußerst wettbewerbsfähigen Preise machten ihre Backup-Lösung zu einer solchen Versuchung für Menschen mit großem Backup-Bedarf. Während ihre Nichteinhaltung ihrer Versprechen möglicherweise Misstrauen ausgelöst hat, gibt es andere Cloud-Anbieter. Aber welchem Anbieter vertrauen Sie Ihr Meme-Archiv an?
Derzeit ist Amazon Web Services (AWS) weltweit führend im Bereich Cloud Computing. Die Lernkurve für AWS kann steil erscheinen, ist aber in Wirklichkeit einfach. Lassen Sie uns herausfinden, wie Sie die weltweit führende Cloud-Plattform nutzen können.
Einfache Speicherlösung
Die einfache Speicherlösung, allgemein als S3 bezeichnet, ist das Ungetüm von Amazon für eine Speicherlösung. Einige bemerkenswerte Unternehmen, die S3 verwenden, sind Tumblr, Netflix, SmugMug und natürlich Amazon.com. Wenn Ihr Kiefer immer noch an Ihrem Gesicht befestigt ist, garantiert AWS für seine Standardoption eine Haltbarkeit von 99,99999999999 Prozent und eine maximale Dateigröße (einer einzelnen Datei) von fünf Terabyte (5 TB). S3 ist ein Objektspeicher, dh er ist nicht für die Installation und Ausführung eines Betriebssystems konzipiert, sondern perfekt für Backups geeignet.
Die Ebenen und Preise
Dies ist bei weitem der komplizierteste Teil von S3. Die Preise variieren von Region zu Region. In unserem Beispiel werden die aktuellen Preise für die Region USA (North Virginia) verwendet. Schauen Sie sich diese Tabelle an:

S3 besteht aus vier Speicherklassen. Standard offensichtlich ist die Standardoption. Selten zugegriffen Das Speichern Ihrer Daten ist insgesamt billiger, das Ein- und Auslesen Ihrer Daten jedoch teurer. Reduzierte Redundanz wird im Allgemeinen für Daten verwendet, die Sie bei Verlust neu generieren können, z. B. Miniaturbilder. Gletscher wird für die Archivierung verwendet, da es am billigsten zu speichern ist. Es dauert jedoch drei bis fünf Stunden, bis Sie eine Datei vom Glacier abrufen können. Durch Gletscher- oder Kühllager werden die Kosten pro Gigabyte gesenkt, aber die Nutzungskosten erhöht. Dadurch eignet sich Cold Storage besser für Archivierung und Disaster Recovery. Unternehmen nutzen im Allgemeinen eine Kombination aller Klassen, um die Kosten weiter zu senken.
Das Beste in jeder Kategorie ist blau markiert. Haltbarkeit ist, wie unwahrscheinlich es ist, dass Ihre Datei verloren geht. Bar Reduzierte Redundanz, Amazon muss in zwei Rechenzentren einen katastrophalen Verlust erleiden, bevor Ihre Daten verloren gehen. Grundsätzlich speichert AWS Ihre Daten in mehreren Einrichtungen mit allen Klassen außer der reduzierten Redundanzklasse. Verfügbarkeit ist, wie unwahrscheinlich es zu Ausfallzeiten kommt. Der Rest wird anhand eines Beispiels leichter demonstriert.
Beispiel Verwendung
Unser Anwendungsfall ist wie folgt.
Ich möchte zehn Dateien auf S3 Standard mit einer Gesamtgröße von einem Gigabyte (1 GB) speichern. Hochladen der Dateien oder Stellen Die Anfrage kostet 0,005 USD und 0,039 USD für den gesamten Speicher. Das bedeutet, dass Ihnen im ersten Monat insgesamt etwa 4,5 Cent (0,044 USD) und knapp 4 Cent (0,039 USD) für das anschließende Parken Ihrer Daten berechnet werden.
Warum gibt es eine so komplizierte Preisstruktur? Dies liegt daran, dass es für das bezahlt wird, was Sie verwenden. Sie zahlen niemals für etwas, das Sie nicht verwenden. Wenn Sie an ein großes Unternehmen denken, bietet dies alle Vorteile einer erstklassigen Speicherlösung bei gleichzeitig minimalen Kosten. Amazon bietet auch eine Einfacher Monatsrechner welche finden Sie hierSo können Sie Ihre monatlichen Ausgaben projizieren. Glücklicherweise bieten sie auch eine kostenlose Stufe an, für die Sie sich hier anmelden könnenSo können Sie ihre Dienste bis zu 12 Monate lang testen. Wie bei allem Neuen wird es umso komfortabler und verständlicher, sobald Sie es verwenden.
Die Konsole
Mit der kostenlosen Stufe von AWS können Sie alle ihre Dienste bis zu einem gewissen Grad ein ganzes Jahr lang ausprobieren. Innerhalb der kostenlosen Stufe bietet S3 5 GB Speicherplatz, 20.000 Gets und 2.000 Puts. Dies sollte ausreichend Raum zum Atmen bieten, um AWS zu testen und zu entscheiden, ob es Ihren Anforderungen entspricht. Die Anmeldung bei AWS führt Sie durch einige Schritte. Sie benötigen eine gültige Kredit- oder Debitkarte und ein Telefon zur Überprüfung. Sobald Sie die Verwaltungskonsole starten, werden Sie im AWS-Dashboard begrüßt.
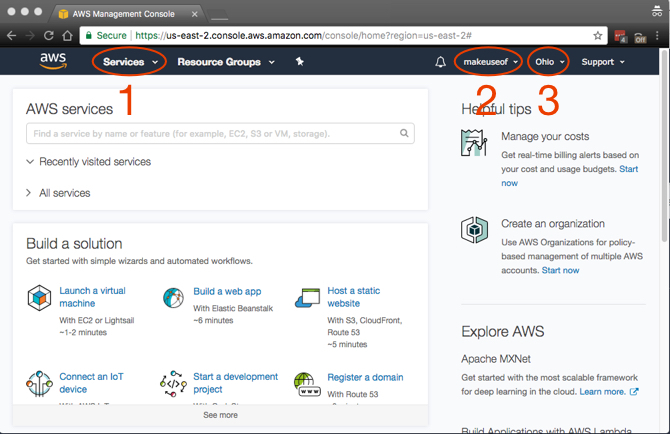
Auf den ersten Blick scheint es, als gäbe es eine Menge zu erledigen, und das liegt einfach daran, dass es eine gibt. Die wichtigsten Elemente, auf die Sie zugreifen werden und die im Screenshot mit Anmerkungen versehen sind, sind:
- Dienstleistungen: Überraschung, Überraschung, hier finden Sie alle AWS-Services.
- Konto: Zugriff auf Ihr Profil und Abrechnung.
- Region: Dies ist die AWS-Region, in der Sie arbeiten.
Wählen Sie eine Region aus, die Ihnen am nächsten liegt, da Sie die geringste Latenz zwischen Ihren Computern und AWS wünschen. Es gibt einige Regionen, in denen nicht alle AWS-Services verfügbar sind, die jedoch laufend eingeführt werden. Zum Glück ist S3 in allen Regionen verfügbar!
S3 Sicherheit
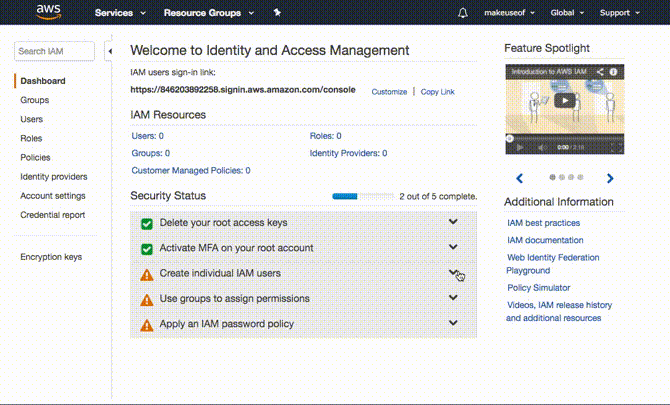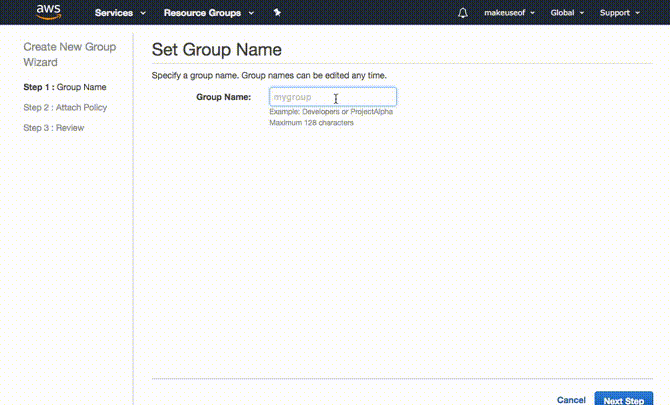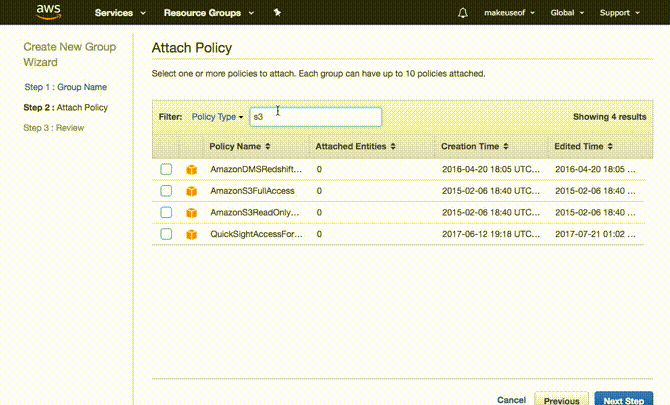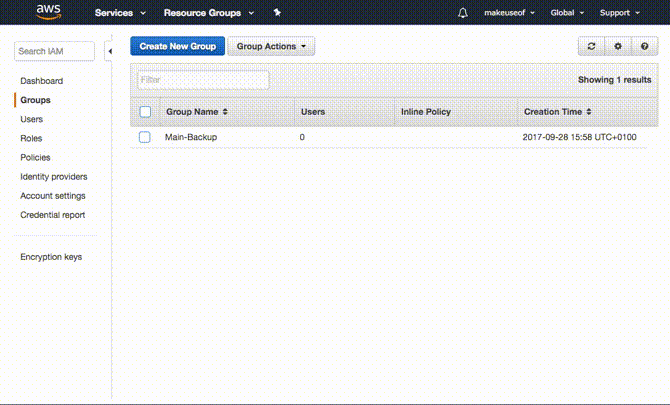
Bevor Sie fortfahren, müssen Sie zunächst Ihr Konto sichern. Klicke auf Services> Sicherheit, Identität und Compliance> IAM. Dabei erteilen wir Ihrem Computer auch die erforderlichen Berechtigungen, damit Sie sicher sichern und wiederherstellen können.

Dies ist ein einfacher fünfstufiger Prozess. Auf dem Screenshot sehen Sie, dass MFA in Ihrem Konto aktiviert werden kann. Obwohl Multi-Faktor-Authentifizierung (MFA), auch bekannt als Zwei-Faktor-Authentifizierung (2FA) So sichern Sie Linux Ubuntu mit Zwei-Faktor-AuthentifizierungMöchten Sie eine zusätzliche Sicherheitsebene für Ihr Linux-Login? Dank Google Authenticator ist es möglich, Ihrem Ubuntu-PC (und anderen Linux-Betriebssystemen) eine Zwei-Faktor-Authentifizierung hinzuzufügen. Weiterlesen ist nicht erforderlich, wird dringend empfohlen. Kurz gesagt, es erfordert eine Kombination aus Benutzername und Passwort sowie einen Code auf Ihrem Mobilgerät. Sie können entweder ein kompatibles physisches MFA-Gerät erwerben oder eine App wie Google Authenticator verwenden. Gehe entweder zum Appstore oder der Spielladen um die Google Authenticator App herunterzuladen.
Verwenden der optionalen Multi-Faktor-Authentifizierung
Erweitern Aktivieren Sie MFA in Ihrem Root-Konto und klicken Sie auf MFA verwalten. Stelle sicher Ein virtuelles MFA-Gerät ausgewählt ist und klicken Nächster Schritt.
Öffnen Sie Google Authenticator auf Ihrem Gerät und scannen Sie den auf dem Bildschirm angezeigten Barcode. Geben Sie den Autorisierungscode in das Feld ein Autorisierungscode 1 und warten Sie, bis der Code in Google Authenticator aktualisiert wurde. Es dauert ungefähr 30 Sekunden, bis der nächste Code angezeigt wird. Geben Sie den neuen Code in das Feld ein Autorisierungscode 2 Box von Google Authenticator. Klicken Sie nun auf die Aktivieren Sie Virtual MFA Taste. Sobald Sie Ihren Bildschirm aktualisiert haben, wird bei MFA aktivieren das grüne Häkchen angezeigt.

Sie sollten jetzt MFA in Ihrem Konto aktiviert und den Google Authenticator mit AWS verknüpft haben. Wenn Sie sich das nächste Mal bei der AWS Console anmelden, geben Sie Ihren Benutzernamen und Ihr Kennwort wie gewohnt ein. AWS fordert Sie dann zur Eingabe eines MFA-Codes auf. Dies wird von der Google Authenticator-App wie im vorherigen Schritt abgerufen.
Gruppen und Berechtigungen
Es ist Zeit zu entscheiden, wie viel Zugriff Ihr Computer auf AWS haben soll. Der einfachste und sicherste Weg, dies zu tun, besteht darin, eine zu erstellen Gruppe und ein Nutzer für den Computer, den Sie sichern möchten. Gewähren Sie dann Zugriff oder fügen Sie dieser Gruppe eine Berechtigung hinzu, nur auf S3 zuzugreifen. Dieser Ansatz bietet zahlreiche Vorteile. Die Anmeldeinformationen für diese Gruppe sind auf S3 beschränkt und können nicht für den Zugriff auf andere AWS-Services verwendet werden. In dem unglücklichen Fall, dass Ihre Anmeldeinformationen verloren gehen, müssen Sie nur den Zugriff der Gruppe löschen, und Ihr AWS-Konto ist sicher.
Es ist tatsächlich sinnvoller, zuerst die Gruppe zu erstellen. Dazu erweitern Erstellen Sie einzelne IAM-Benutzer und klicken Sie auf Benutzer verwalten. Klicke auf Gruppen von der Tafel links gefolgt von neue Gruppe erstellen. Wählen Sie einen Namen für Ihre Gruppe und klicken Sie auf Nächster Schritt. Jetzt fügen wir die Berechtigung oder Richtlinie für diese Gruppe hinzu. Da diese Gruppe nur Zugriff auf S3 haben soll, filtern Sie die Liste durch Eingabe S3 im Filter. Sicher gehen, dass AmazonS3FullAccess ausgewählt ist und klicken Nächster Schritt schließlich gefolgt von Gruppe erstellen.
Erstellen Sie einen Benutzer
Jetzt müssen Sie nur noch einen Benutzer erstellen und ihn der von Ihnen erstellten Gruppe hinzufügen. Wählen Benutzer Klicken Sie im linken Bereich auf Benutzer hinzufügen. Wählen Sie einen beliebigen Benutzernamen und stellen Sie unter Zugriffstyp sicher, dass Programmatischer Zugriff ausgewählt ist und klicken Weiter: Berechtigungen. Wählen Sie auf der nächsten Seite die von Ihnen erstellte Gruppe aus und klicken Sie auf Weiter: Überprüfen. AWS bestätigt, dass Sie diesen Benutzer zur ausgewählten Gruppe hinzufügen, und bestätigt die erteilten Berechtigungen. Klicke auf Benutzer erstellen um zur nächsten Seite zu gelangen.
Sie sehen jetzt eine Zugriffsschlüssel-ID und ein Geheimer Zugangsschlüssel. Diese werden selbst generiert und nur einmal angezeigt. Sie können sie entweder kopieren und an einem sicheren Ort einfügen oder auf klicken Laden Sie .csv herunter Dadurch wird eine Tabelle mit diesen Details heruntergeladen. Dies entspricht dem Benutzernamen und dem Kennwort, mit denen Ihr Computer auf S3 zugreift.
Es ist erwähnenswert, dass Sie diese mit dem höchsten Maß an Sicherheit behandeln sollten. Wenn Sie Ihren geheimen Zugriffsschlüssel verlieren, können Sie ihn nicht mehr abrufen. Sie müssen zur AWS-Konsole zurückkehren und eine neue generieren.

Dein erster Eimer
Es ist an der Zeit, einen Ort für Ihre Daten zu schaffen. S3 hat Geschäfte, die Eimer genannt werden. Jeder Bucket-Name muss global eindeutig sein. Wenn Sie also einen Bucket erstellen, sind Sie der einzige auf dem Planeten mit diesem Bucket-Namen. Für jeden Bucket können eigene Konfigurationsregeln festgelegt werden. Du kannst haben Versionierung In Buckets aktiviert, damit Kopien der von Ihnen aktualisierten Dateien erhalten bleiben, sodass Sie zu früheren Versionen von Dateien zurückkehren können. Es gibt auch Optionen für Regionsübergreifende Replikation Damit können Sie Ihre Daten in einer anderen Region in einem anderen Land weiter sichern.
Sie können zu S3 gelangen, indem Sie zu navigieren Dienste> Speicher> S3. Das Erstellen eines Buckets ist so einfach wie das Klicken auf Eimer erstellen Taste. Nachdem Sie einen global eindeutigen Namen ausgewählt haben (nur in Kleinbuchstaben), wählen Sie eine Region aus, in der Ihr Eimer leben soll. Klicken Sie auf die Erstellen Knopf gibt Ihnen endlich Ihren ersten Eimer.

Kommandozeile ist Leben
Wenn Kommandozeile ist Ihre Waffe der Wahl 4 Möglichkeiten, sich Terminalbefehle unter Linux beizubringenWenn Sie ein echter Linux-Master werden möchten, ist es eine gute Idee, über Terminalkenntnisse zu verfügen. Hier Methoden, mit denen Sie anfangen können, sich selbst zu unterrichten. Weiterlesen können Sie mit auf Ihren neu erstellten S3-Bucket zugreifen s3cmd was du kannst hier herunterladen. Nachdem Sie die neueste Version ausgewählt haben, laden Sie das Zip-Archiv in einen Ordner Ihrer Wahl herunter. Die aktuellste Version ist 2.0.0, die Sie in unserem Beispiel verwenden werden. Um s3cmd zu entpacken und zu installieren, öffnen Sie ein Terminalfenster und geben Sie Folgendes ein:
sudo apt installiert python-setuptools. entpacke s3cmd-2.0.0. cd s3cmd-2.0.0. sudo python setup.py installierens3cmd ist jetzt auf Ihrem System installiert und kann konfiguriert und mit Ihrem AWS-Konto verknüpft werden. Stellen Sie sicher, dass Sie Ihre haben Zugriffsschlüssel-ID und Geheimer Zugangsschlüssel ab dem Zeitpunkt, an dem Sie Ihren Benutzer erstellt haben. Beginnen Sie mit der Eingabe von:
s3cmd --configureSie werden nun aufgefordert, einige Details einzugeben. Zunächst werden Sie aufgefordert, Ihre Zugangsschlüssel-ID gefolgt von Ihrem geheimen Zugangsschlüssel einzugeben. Alle anderen Einstellungen können standardmäßig durch einfaches Drücken der Eingabetaste beibehalten werden, mit Ausnahme der Verschlüsselung Rahmen. Sie können hier ein Passwort wählen, damit die in und aus S3 gesendeten Daten verschlüsselt werden. Dies verhindert a Mann im mittleren Angriff Fünf Online-Verschlüsselungstools zum Schutz Ihrer Privatsphäre Weiterlesen oder jemand, der Ihren Internetverkehr abfängt.
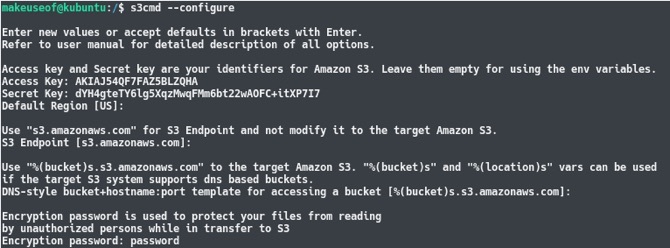
Am Ende des Konfigurationsprozesses führt s3cmd einen Test durch, um sicherzustellen, dass alle Einstellungen funktionieren und Sie erfolgreich eine Verbindung zu Ihrem AWS-Konto herstellen können. Wenn dies erledigt ist, können Sie einige Befehle eingeben wie:
s3cmd lsDadurch werden alle Buckets in Ihrem S3-Konto aufgelistet. Wie der Screenshot unten zeigt, ist der von Ihnen erstellte Bucket sichtbar!

Mit der Befehlszeile synchronisieren
Der Synchronisierungsbefehl für s3cmd ist äußerst vielseitig. Es ähnelt sehr dem normalen Kopieren einer Datei unter Linux und sieht ungefähr so aus:
s3cmd sync [LOKALER WEG] [FERNWEG] [PARAMETER]Testen Sie die Verwendung mit einer einfachen Synchronisierung. Erstellen Sie zunächst zwei Textdateien mit berühren Befehl, dann verwenden Sie die synchronisieren Befehl zum Senden der gerade erstellten Dateien in den zuvor erstellten Bucket. Aktualisieren Sie den S3-Bucket. Sie werden feststellen, dass die Dateien tatsächlich an S3 gesendet wurden! Stellen Sie sicher, dass Sie den lokalen Pfad durch den lokalen Pfad auf Ihrem Computer ersetzen und den Remote-Pfad in Ihren Bucket-Namen ändern. Um diesen Typ zu erreichen:
Berühren Sie Datei-1.txt. Berühren Sie Datei-2.txt. s3cmd sync ~ / Backup s3: // makeuseof-backup
Das synchronisieren Der Befehl überprüft und vergleicht zunächst beide Verzeichnisse. Wenn eine Datei in S3 nicht vorhanden ist, wird sie hochgeladen. Wenn eine Datei vorhanden ist, wird vor dem Kopieren in S3 überprüft, ob sie aktualisiert wurde. Wenn Sie möchten, dass auch die lokal gelöschten Dateien gelöscht werden, können Sie den Befehl mit dem ausführen –Löschen entfernt Parameter. Testen Sie dies, indem Sie zuerst eine der von uns erstellten Textdateien löschen, gefolgt vom Befehl sync mit dem zusätzlichen Parameter. Wenn Sie dann Ihren S3-Bucket aktualisieren, wurde die gelöschte Datei jetzt aus S3 entfernt! Geben Sie dazu Folgendes ein:
rm file-1.txt. s3cmd sync ~ / Backup s3: // makeuseof-backup - löschen-entfernt
Auf einen Blick sehen Sie, wie überzeugend diese Methode ist. Wenn Sie etwas in Ihrem AWS-Konto sichern möchten, können Sie dies tun Fügen Sie den Synchronisierungsbefehl einem Cron-Job hinzu So planen Sie Aufgaben unter Linux mit Cron und CrontabDie Fähigkeit, Aufgaben zu automatisieren, ist eine dieser futuristischen Technologien, die es bereits gibt. Jeder Linux-Benutzer kann dank cron, einem benutzerfreundlichen Hintergrunddienst, von der Planung von System- und Benutzeraufgaben profitieren. Weiterlesen und sichern Sie Ihren Computer automatisch auf S3.
Die GUI-Alternative
Wenn die Befehlszeile nicht Ihr Ding ist, gibt es eine Alternative zur grafischen Benutzeroberfläche (GUI) zu s3cmd: Cloud Explorer. Es verfügt zwar nicht über eine sehr moderne Benutzeroberfläche, bietet jedoch einige interessante Funktionen. Ironischerweise ist die einfachste Methode, um an die neueste Version zu gelangen, die Befehlszeile. Wenn Sie ein Terminalfenster mit einem Ordner geöffnet haben, in dem Sie es installieren möchten, geben Sie Folgendes ein:
sudo apt -y installieren Wie man APT benutzt und sich von APT-GET in Debian und Ubuntu verabschiedetLinux befindet sich in einem permanenten Entwicklungsstadium. Wichtige Änderungen werden manchmal leicht übersehen. Während einige Verbesserungen überraschend sein können, sind andere einfach sinnvoll: Schauen Sie sich diese Änderungen an und sehen Sie, was Sie denken. Weiterlesen openjdk-8-kopfloser Ameisengit. Git-Klon https://github.com/rusher81572/cloudExplorer.git. cd cloudExplorer. Ameise. cd dist. java -jar CloudExplorer.jarBeim Start der Benutzeroberfläche sollten einige der erforderlichen Felder bereits bekannt sein. Um Ihr AWS-Konto zu laden, geben Sie Ihren Zugriffsschlüssel und Ihren geheimen Schlüssel ein, geben Sie einen Namen für Ihr Konto ein und klicken Sie auf speichern.
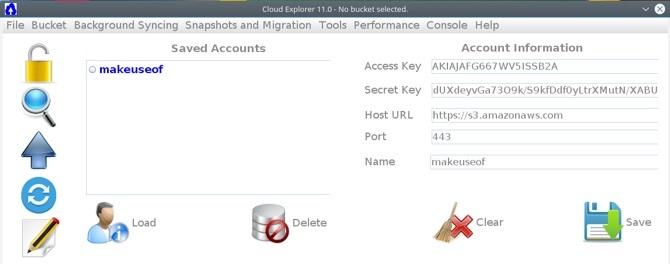
Sie können jetzt auf Ihr gespeichertes Profil klicken und Zugriff auf Ihren Bucket erhalten.
Den Explorer erkunden
Wenn Sie einen kurzen Blick auf die Benutzeroberfläche werfen, sehen Sie Folgendes:
- Ausloggen
- Entdecken und suchen
- Daten hochladen
- Synchronisieren
- Texteditor
- Ein Panel für eine Liste Ihrer Eimer
- Ein Bedienfeld zum Navigieren in einem ausgewählten Bucket

Das Einrichten der Synchronisierungsfunktionen von Cloud Explorer ähnelt s3cmd. Erstellen Sie zunächst eine Datei, die im S3-Bucket nicht vorhanden ist. Klicken Sie dann auf Synchronisieren Klicken Sie im Cloud Explorer auf die Schaltfläche und navigieren Sie zu dem Ordner, den Sie mit S3 synchronisieren möchten. Klicken Sie auf Zu S3 überprüft die Unterschiede zwischen dem Ordner auf Ihrem lokalen Computer und dem Ordner mit S3 und lädt alle gefundenen Unterschiede hoch.
Wenn Sie den S3-Bucket im Browser aktualisieren, werden Sie feststellen, dass die neue Datei an S3 gesendet wurde. Leider berücksichtigt die Synchronisierungsfunktion von Cloud Explorer keine Dateien, die Sie auf Ihrem lokalen Computer gelöscht haben. Wenn Sie also eine Datei lokal entfernen, bleibt sie weiterhin in S3. Dies ist etwas zu beachten.

Privatanwender können geschäftsorientierten Cloud-Speicher verwenden
Während AWS eine Lösung ist, mit der Unternehmen die Cloud nutzen können, gibt es keinen Grund, warum Heimanwender nicht in die Aktion einsteigen sollten. Die Nutzung der weltweit führenden Cloud-Plattform bietet viele Vorteile. Sie müssen sich nie darum kümmern, die Hardware zu aktualisieren oder für etwas zu bezahlen, das Sie nicht verwenden. Eine weitere interessante Tatsache ist, dass AWS mehr Marktanteile hat als die nächsten 10 Anbieter zusammen. Dies ist ein Hinweis darauf, wie weit sie voraus sind. Das Einrichten von AWS als Sicherungslösung erfordert:
- Ein Profil erstellen.
- Sichern Sie Ihr Konto bei MFA.
- Erstellen einer Gruppe und Zuweisen von Berechtigungen zur Gruppe.
- Hinzufügen eines Benutzers zur Gruppe.
- Erstellen Sie Ihren ersten Eimer.
- Verwenden der Befehlszeile zum Synchronisieren mit S3.
- Eine GUI-Alternative für S3.
Verwenden Sie AWS derzeit für irgendetwas? Welchen Cloud-Backup-Anbieter verwenden Sie derzeit? Nach welchen Funktionen suchen Sie bei der Auswahl eines Backup-Anbieters? Lass es uns in den Kommentaren unten wissen!
Yusuf möchte in einer Welt voller innovativer Unternehmen, Smartphones mit dunklem Röstkaffee und Computern mit hydrophoben Kraftfeldern leben, die zusätzlich Staub abweisen. Als Business Analyst und Absolvent der Durban University of Technology mit über 10 Jahren Erfahrung in einer schnell wachsenden Technologiebranche ist er gerne der Mittler zwischen…