Werbung
Wir können jetzt mit fast allen unseren Geräten sprechen, aber wie funktioniert das genau? Wenn du fragst "Welches Lied ist das?" oder sagen Sie "Call Mom", ein Wunder der modernen Technologie geschieht. Und obwohl es sich so anfühlt, als wäre es auf dem neuesten Stand, reicht diese Idee, mit Geräten zu sprechen, Jahrzehnte zurück - fast so weit wie Jetpacks in der Science-Fiction!
Heutzutage liegt der größte Teil der Aufmerksamkeit für sprachgesteuertes Computing auf Smartphones. Apple, Amazon, Microsoft und Google stehen an der Spitze der Kette und bieten jeweils ihre eigene Möglichkeit, mit der Elektronik zu kommunizieren. Sie wussten, wer sie sind: Siri, Alexa, Cortana und das namenlose Wesen „Ok, Google“. Was eine große Frage aufwirft ...
Wie nimmt ein Gerät gesprochene Wörter und wandelt sie in Befehle um, die es verstehen kann? Im Wesentlichen kommt es darauf an, Muster abzugleichen und Vorhersagen auf der Grundlage dieser Muster zu treffen. Insbesondere ist die Spracherkennung eine komplexe Aufgabe Akustische Modellierung und Sprachmodellierung.
Akustische Modellierung: Wellenformen und Telefone
Akustische Modellierung ist der Prozess, bei dem eine Sprachform der Sprache mithilfe statistischer Modelle analysiert wird. Die gebräuchlichste Methode hierfür ist Versteckte Markov-Modellierung, die in so genannten verwendet wird Aussprachemodellierung die Sprache in Bestandteile zu zerlegen, die als Telefone bezeichnet werden (nicht zu verwechseln mit tatsächlichen Telefongeräten). Microsoft ist seit vielen Jahren ein führender Forscher auf diesem Gebiet.
Hidden Markov Modeling: Wahrscheinlichkeitszustände
Hidden Markov Modeling ist ein prädiktives mathematisches Modell, bei dem der aktuelle Zustand durch Analyse der Ausgabe bestimmt wird. Wikipedia hat eine tolles Beispiel mit zwei Freunden.
Stellen Sie sich zwei Freunde vor - Local Friend und Remote Friend - die in verschiedenen Städten leben. Ein lokaler Freund möchte herausfinden, wie das Wetter dort ist, wo Remote Friend lebt, aber Remote Friend möchte nur darüber sprechen, was er an diesem Tag getan hat: spazieren gehen, einkaufen oder putzen. Die Wahrscheinlichkeit jeder Aktivität hängt vom Wetter des Tages ab.
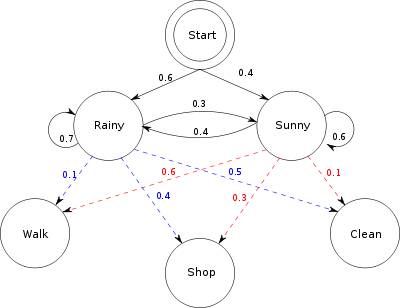
Stellen Sie sich vor, dies sei die einzige verfügbare Information. Damit kann Local Friend Trends finden, wie sich das Wetter von Tag zu Tag verändert hat, und diese Trends nutzen, sagt sie kann anfangen, fundierte Vermutungen darüber anzustellen, wie das heutige Wetter auf der gestrigen Aktivität ihrer Freundin basieren wird. (Sie können ein Diagramm des Systems oben sehen.)
Wenn Sie ein komplexeres Beispiel wünschen, schauen Sie sich das an Dieses Beispiel auf Matlab. Bei der Spracherkennung vergleicht dieses Modell im Wesentlichen jeden Teil der Wellenform mit dem, was vorher und was nachher kommt, und mit einem Wörterbuch von Wellenformen, um herauszufinden, was gesagt wird.
Wenn Sie einen "th" -Sound erzeugen, wird dieser Sound im Wesentlichen mit den wahrscheinlichsten Sounds verglichen, die normalerweise davor und danach auftreten. Vielleicht bedeutet das, gegen den "e" -Ton, den "at" -Ton und so weiter zu prüfen. Wenn das Muster richtig übereinstimmt, hat es Ihr ganzes Wort. Dies ist eine übermäßige Vereinfachung, aber Sie können sehen Die ganze Erklärung von Microsoft hier.
Sprachmodellierung: Mehr als Klang
Die akustische Modellierung trägt wesentlich dazu bei, dass Ihr Computer Sie versteht. Wie steht es jedoch mit Homonymen und regionalen Unterschieden in der Aussprache? Hier kommt die Sprachmodellierung ins Spiel. Google hat eine Menge Forschung in diesem Bereich vorangetrieben, hauptsächlich durch die Verwendung von N-Gramm-Modellierung.
Wenn Google versucht, Ihre Sprache zu verstehen, basiert dies auf Modellen, die aus seiner riesigen Anzahl von Sprachsuch- und YouTube-Transkriptionen abgeleitet wurden. All diese unglaublich falschen Videotitel haben Google tatsächlich dabei geholfen, ihre Wörterbücher weiterzuentwickeln. Auch sie benutzten die Verstorbenen Toget-411 Informationen darüber zu sammeln, wie Menschen sprechen.

Die gesamte Sprachsammlung hat eine Vielzahl von Aussprachen und Dialekten erstellt, die ein robustes Wörterbuch mit Wörtern und deren Klang ergeben. Dies ermöglicht Übereinstimmungen, die eine stark reduzierte Fehlerrate aufweisen als Brute-Force-Übereinstimmungen basierend auf Rohwahrscheinlichkeiten. Sie können eine kurze Arbeit lesen beschreiben hier ihre Methoden.
Während Google auf diesem Gebiet führend ist, werden andere mathematische Modelle entwickelt, einschließlich des kontinuierlichen Raums Modelle und Positionssprachenmodelle, die fortgeschrittenere Techniken sind, die aus der Forschung in der künstlichen Intelligenz hervorgegangen sind. Diese Methoden basieren auf der Replikation der Argumentation, die Menschen machen, wenn sie einander zuhören. Diese sind sowohl in Bezug auf die dahinter stehende Technologie als auch in Bezug auf die Mathematik und Programmierung, die für die Abbildung dieser Modelle erforderlich sind, viel weiter fortgeschritten.
N-Gramm-Modellierung: Wahrscheinlichkeit trifft auf Speicher
Die N-Gramm-Modellierung basiert auf Wahrscheinlichkeiten, verwendet jedoch ein vorhandenes Wortwörterbuch, um einen verzweigten Baum von Möglichkeiten zu erstellen, der dann aus Gründen der Effizienz geglättet wird. In gewisser Weise bedeutet dies, dass die N-Gramm-Modellierung einen Großteil der Unsicherheit bei der oben genannten Hidden-Markov-Modellierung beseitigt.
Wie oben erwähnt, liegt die Stärke dieser Methode in einem großen Wörterbuch von Wörter und Verwendungszweck, nicht nur primitiv Geräusche. Dies gibt dem Programm die Möglichkeit, den Unterschied zwischen Homophonen wie „Beat“ und „Beet“ zu erkennen. Es ist kontextbezogen, was bedeutet, dass das Programm, wenn Sie über die Ergebnisse der letzten Nacht sprechen, keine Worte über Borschtsch spricht.
Diese Modelle sind jedoch nicht die besten für die Sprache, hauptsächlich aufgrund von Problemen mit der Wahrscheinlichkeit von Wörtern in längeren Phrasen. Wenn Sie einem Satz mehr Wörter hinzufügen, gerät dieses Modell etwas ins Wanken, da Ihre frühen Wörter wahrscheinlich nicht alles geladen haben, was Sie für Ihren vollständigen Gedanken benötigen.
Es ist jedoch einfach und leicht zu implementieren, was es zu einer großartigen Ergänzung für ein Unternehmen wie Google macht, das gerne Server auf Rechenprobleme stürzt. Weitere Informationen zu N-Gramm Modelieng finden Sie im Universität von Washington, oder Sie können eine sehen Vortrag bei Coursera.
Clouds anschreien: Apps & Geräte
Jeder, der Siri verwendet hat, kennt die Frustration einer langsamen Netzwerkverbindung. Dies liegt daran, dass Ihre Befehle an Siri über das Netzwerk gesendet werden, um von Apple dekodiert zu werden. Für Cortana für Windows Phone ist außerdem eine Netzwerkverbindung erforderlich, um ordnungsgemäß zu funktionieren. Im Gegensatz dazu ist Amazon Echo jedoch nur ein Bluetooth-Lautsprecher ohne Internet.
Warum der Unterschied? Weil Siri und Cortana Hochleistungsserver benötigen, um Ihre Sprache zu entschlüsseln. Könnte es auf Ihrem Telefon oder Tablet gemacht werden? Sicher, aber Sie würden dabei Ihre Leistung und Akkulaufzeit beeinträchtigen. Es ist nur sinnvoller, die Verarbeitung auf dedizierte Maschinen zu verlagern.
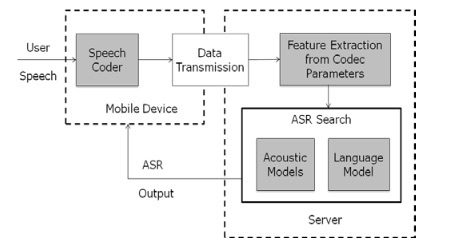
Stellen Sie sich das so vor: Ihr Befehl ist ein Auto, das im Schlamm steckt. Sie könnten es wahrscheinlich mit genügend Zeit und Mühe selbst herausschieben, aber es wird Stunden dauern und Sie erschöpfen. Stattdessen rufen Sie die Pannenhilfe an und sie ziehen Ihr Auto in wenigen Minuten heraus. Der Nachteil ist, dass Sie den Anruf tätigen und auf sie warten müssen, aber es ist immer noch schneller und weniger anstrengend.
Desktop-Modelle wie Nuance verwenden aufgrund der leistungsstärkeren Hardware in der Regel lokale Ressourcen. Immerhin, in den Worten von Steve Jobs, Ihr Desktop ist ein LKW. (Was es ein bisschen albern macht, dass OS X verwendet Server für seine Verarbeitung.) Wenn Sie also Sprache und Sprache verarbeiten müssen, ist sie bereits gut genug ausgestattet, um sie selbst zu handhaben.
Auf der anderen Seite ermöglicht Android Entwicklern, die Offline-Spracherkennung in ihre Apps aufzunehmen. Google ist gerne der Technologie voraus, und Sie können darauf wetten, dass die anderen Plattformen diese Fähigkeit erhalten, wenn ihre Hardware leistungsfähiger wird. Niemand mag es, wenn schlechte Abdeckung oder schlechter Empfang sein Gerät lobotomisieren.
Starten Sie jetzt die Verwendung von Sprachbefehlen
Nachdem Sie die grundlegenden Konzepte kennen, sollten Sie mit Ihren verschiedenen Geräten herumspielen. Probieren Sie das Neue aus Spracheingabe in Google Text & Tabellen Wie Voice Typing die neue beste Funktion von Google Text & Tabellen istDie Spracherkennung hat sich in den letzten Jahren sprunghaft verbessert. Anfang dieser Woche hat Google endlich die Spracheingabe in Google Text & Tabellen eingeführt. Aber ist es gut? Lass es uns herausfinden! Weiterlesen . Als ob die Web Office Suite noch nicht leistungsfähig genug wäre, können Sie mit der Sprachsteuerung Ihre Dokumente vollständig diktieren und formatieren. Dies erweitert die leistungsstarke Technologie, die sie bereits für Chrome und Android entwickelt haben.
Weitere Ideen sind das Einrichten Ihres Mac zur Verwendung von Sprachbefehlen So verwenden Sie Sprachbefehle auf Ihrem Mac Weiterlesen und einrichten Sie Ihre Amazon Echo mit automatisierter Kaufabwicklung Wie Amazon Echo Ihr Zuhause zu einem Smart Home machen kannSmart Home Tech steckt noch in den Anfängen, aber ein neues Produkt von Amazon namens "Echo" könnte dazu beitragen, es in den Mainstream zu bringen. Weiterlesen . Lebe in der Zukunft und rede gerne mit deinen Geräten - auch wenn du nur mehr Papiertücher bestellst. Wenn Sie süchtig nach Smartphones sind, haben wir auch Tutorials für Siri 8 Dinge, von denen Sie wahrscheinlich nicht gewusst haben, dass Siri sie tun könnteSiri ist zu einer der bestimmenden Funktionen des iPhones geworden, aber für viele Menschen ist es nicht immer die nützlichste. Während ein Teil davon auf die Einschränkungen der Spracherkennung zurückzuführen ist, ist die Seltsamkeit der Verwendung von ... Weiterlesen , Cortana 6 coolsten Dinge, die Sie mit Cortana in Windows 10 steuern könnenMit Cortana können Sie unter Windows 10 freihändig arbeiten. Sie können sie Ihre Dateien und das Internet durchsuchen lassen, Berechnungen durchführen oder die Wettervorhersage abrufen. Hier behandeln wir einige ihrer cooleren Fähigkeiten. Weiterlesen , und Android OK, Google: 20 nützliche Dinge, die Sie Ihrem Android-Handy sagen könnenMit Google Assistant können Sie viel auf Ihrem Handy erledigen. Hier finden Sie eine ganze Reihe grundlegender, aber nützlicher OK-Google-Befehle zum Ausprobieren. Weiterlesen .
Was ist Ihre Lieblingsanwendung der Sprachsteuerung? Lass es uns in den Kommentaren wissen.
Bildnachweis: T-Flex über Shutterstock, Terencehonles über die Wikimedia Foundation, Arizona State, Cienpies Design über Shutterstock
Michael hat keinen Mac benutzt, als sie zum Scheitern verurteilt waren, aber er kann in Applescript codieren. Er hat Abschlüsse in Informatik und Englisch; Er schreibt schon seit einiger Zeit über Mac, iOS und Videospiele. und er ist seit über einem Jahrzehnt ein IT-Affe am Tag, der sich auf Skripte und Virtualisierung spezialisiert hat.


